
This is the first in a short series of posts that explain Project Database Unique IDs (PDUIDs). This post explains the purpose of PDUIDs and their structure. Later posts will explain:
- How PDUIDs can be viewed
- How they can be used in operations in Cradle tools, API and WSI
- How PDUIDs can be changed or preserved when information is moved between databases
Identifying Information
Each piece of information must be distinguishable from all other pieces of information so we can be sure we have found what we were searching for. We do this by marking each piece of information in a unique way.
For information in databases, the markings are unique values called keys or identities. A piece of information can have multiple identities, each for a different purpose. For example, although a company’s payroll system is likely to identify each person by a unique Employee ID, each person’s details will also include their governmental tax ID (such as a National Insurance number, a Unique Taxpayer Reference, a Sozialversicherungsnummer or a Social Security Number). This tax ID will also be unique and so could also be used as an identity for that person’s information.
Cradle has two forms of identity, item identities and Project Database Unique IDs (PDUIDs).
Database and Host Identities
Every Cradle system has a Cradle Database Server (CDS) to manage the information in its databases. The CDS is locked to a Host ID, the last 8 digits of the MAC address of the host’s primary network interface.
All databases in a Cradle system share a common Database ID (DID), a 10-character ID of the form:
Platform ID Host ID
where:
| Platform ID | : | CDS’s platform, 02 for Windows or 17 for Linux (other values are for obsolete platforms such as Domain/OS, SunOS, Solaris, HP-UX, Ultrix, SCO, OSF/1 and VMS) |
| Host ID | : | CDS’s host ID, also used in the system’s Security Code |
For example: 1750D4FA4C
The role of a DID is to differentiate information in a database managed by one CDS from information in databases managed by any other CDS, even if all other particulars of the information are the same, such as they are the same item of the same item type in the same project in these disparate Cradle systems.
A common example is when organisations send information to each other, such as customers and suppliers. This creates two copies, or instances, of each piece of information. The databases’ DIDs differentiate the instances held by the customer and suppliers. This is important because:
- An organisation cannot know if other organisations have changed information
- It is important to know which organisations hold each piece of information and which pieces of information each organisation holds
- It may be appropriate to designate one instance as primary so its content is authoritative and other instances are secondary
Project Identities
A Cradle system can manage many databases. Each database is used for one or more projects. Each database has a unique 4 character Project Code that is used at login to specify which database is to be accessed.
Separately, a Project ID (PID) can be specified when a database is created using the Project Manager tool, or c_prj utility. This is a 6-character string and is typically similar to the Project Code. It defaults to six underscores:
______
The Project ID can be used to label a database. It can be helpful if databases are related, for example as successive missions in a programme or separate vessels in a class of ships, when related Project IDs could be used:
- ARTEM01
- ARTEM02
- ARTEM03
Role of Project IDs
It is likely that what might appear to be the same information could exist in two or more databases. This could be intentional and helpful, or it could be unhelpful and inconvenient. The fundamental role of a PID is to differentiate between databases:
- In the most common scenario, an organisation uses its standard process in several projects. These projects’ databases will contain the same types of information, such as hierarchies of needs and user requirements, and the same structuring and numbering conventions. It is quite likely that the databases will contain items with the same hierarchical numbers and, for groups and sub-groups, the same names:
- 1 Context
- 1.1 Purpose
- 1.2 Roles
- 1.2.1
- 2 Stakeholders
- 2.1 Purchasers
- 2.2 Operators
Here it is inconvenient that multiple requirement 1.2.1s exist in the databases, each with unrelated contents. Viewing requirement 1.2.1 in isolation could give an incorrect understanding by interpreting it as part of one project when it is actually part of another project.
- In an alternate scenario, two or more databases could be logically related. Indeed one database may be an extension of another, or an evolution of it at a later stage in the project. In this case, viewing information in isolation would not show which database it came from and could also create an incorrect understanding.
In both scenarios, including a PID would differentiate the content of each database from the others.
Item Identities
Cradle databases contain different types of information. The basic unit of information in a Cradle database is the item. Every item has an associated item type that defines the type of information it contains. Projects can create their own item types in the schema that describes the database’s structure and rules. For example:
- HLURs, high level user requirements
- SRs, system requirements
- TEST CASE, description of a test to be run with the steps to perform and their possible outcomes
Collectively the items of such user-defined item types are called system notes.
Identities and Instances
Every item has an identity to uniquely identify it amongst other items. An identity is the combination of the values of several attributes.
Items evolve over time. Projects will usually keep copies of items at different stages in their evolution. Cradle has the concept of instances of an item. Instances are copies of items as they were at some time in the past, typically in previous baselines. In MBSE (model based systems engineering) users can create multiple instances of diagrams and specifications as alternative analyses or designs. These alternatives co-exist until a choice is made between them.
An instance is the combination of:
- A version number, initially empty and increasing 1, 2, 3… through successive baselines
- A draft ID, either A if the item is not in a baseline or empty if the item is baselined. The values B, C … Z are used for alternative diagram and specification items in MBSE analysis or design models.
Structure of an Identity
The identity of an item is:
Item ID Instance ID
where:
| Item ID | : | The collection of attributes that identify a specific item of a given item type |
| Instance ID | : | Which of possibly many instances of the item is being referred to |
The different parts of item identities are:

where:
| Domain ID | : | Either E (for Essential) or I (for Implementation), the domain containing the item’s model |
| Model ID | : | The item’s model, either a numeric Model Unique ID (MUID) or a namespace showing the model in the domain’s model hierarchy, such as: As Built.Prototype A.Architecture |
| Type | : | Either one of the 26 diagram types that Cradle supports such as DFD, eFFBD, UCD, PAD and so on, or a specification type (process specification, environment terminator or module specification) or a user-defined item type such as PRODUCT REQ, SBS or VALIDATION |
| Stereotype | : | Only used by information in SysML models, the item’s stereotype, such as <<actor>>, <<block>>, <<constraint>>, <<message>>, <<package>> and so on |
The item identity is fundamental in Cradle. All other methods of identifying or labelling items, including those described in this document, are secondary to these item identities.
PDUIDs
The above tables show that there are significant differences between the identities of item types. They make specifying and working with identities complex, and do not provide a single sequence of values to identify all items in a database.
These problems are solved by the Project Database Unique ID (PDUID), which:
- Apply to all of the item types
- Have the same format for all of these item types
- Are in a single sequence for all items, for example:
- A PDUID could reference a diagram in a model with namespace B.C (with an equivalent MUID)
- The next PDUID could reference a TEST CASE system note item
- The next PDUID could be a diagram in a namespace Y model (different MUID to the above diagram)
- The next PDUID could reference a change request
- The next PDUID could be a data definition in the model with namespace B.C
PDUID Structure
The format of a PDUID is:
Database ID Project ID Unique ID
where the Database ID and Project ID are as described earlier, and the Unique ID is a number 1, 2, 3… zero-padded to 10 digits. PDUIDs are 26 character strings with the structure:
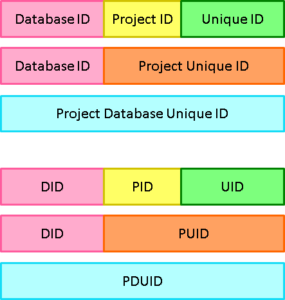
PDUID Examples
Some example PDUIDs:
- 0280A992E5SYSML_0000000022, in which:
- 0280A992E5 : is the DID, the Database ID
- SYSML_ : is the PID, the Project ID
- 0000000022 : is the UID, the Unique ID
- 0280A992E5SYSML_0000000023
- 0280A992E5 : is the DID, the Database ID
- SYSML_ : is the PID, the Project ID
- 0000000023 : is the UID, the Unique ID
- 0280A992E5SYSML_0000000024
- 0280A992E5SYSML_0000000025
Role of PDUID Components
As such, and given their constituent parts:
- The Unique ID enables the PDUID to uniquely identify a database item
- The Project ID enables the PDUID to uniquely identify an item across multiple databases
- The Database ID enables the PDUID to uniquely identify an item between separate Cradle systems, even if everything else about information in the databases in these Cradle systems is the same
PDUIDs as Item Identities
A PDUID identifies an item, but not a specific instance of that item. This is deliberate. It is more convenient if the PDUIDs of all instances of an item are the same. Therefore, an alternative for the identity of an item is:
PDUID Instance ID
which identifies a specific instance of an item, where:
| PDUID | : | Is the item’s PDUID as defined above that identifies an item |
| Instance ID | : | Which of possibly many instances of the item is being referred to, with the same meaning as above |
PDUID Item Identity Examples
As examples, in the example database SYSM:
- There is a use case diagram Automobile Use Case Diagram whose identity is:
- Domain ID: I
- Namespace: SysML-Automobile, which has MUID 100
- Type: uc, meaning a SysML use case diagram
- Stereotype: use case
- Number: uc-1
- Version:
- Draft: A
which has been assigned the PDUID 0280A992E5SYSML_0000000035 so the item’s identity is also:
- PDUID: 0280A992E5SYSML_0000000035
- Version:
- Draft: A
that can also be expressed as:
- Database ID: 0280A992E5
- Project ID: SYSML_, and hence PUID: SYSML_0000000035
- Unique ID: 0000000035
- In the same database there is also a TEST CASE item Keycode verification whose identity is:
- Type: TEST CASE
- Number: TC-20
- Version:
- Draft: A
which has been assigned the PDUID 0280A992E5SYSML_0000000024 so the item’s identity is also:
- PDUID: 0280A992E5SYSML_0000000024
- Version:
- Draft: A
that can also be expressed as:
- Database ID: 0280A992E5
- Project ID: SYSML_, and hence PUID: SYSML_0000000024
- Unique ID: 0000000024
- Version:
- Draft: A
PUIDs
Project Unique ID (PUID) is the name given to the PDUID without its Database ID (DID). In other words, PUIDs are a means to identify pieces of information in a single database.
PDUID Lookup
Every Cradle database contains a table that is used to check if a PDUID has been used and to convert between item identities and PDUIDs. This table is empty when a database is first created. The table is not part of the information in Cradle export files. Rather, the table’s contents are created when items are created in the database, either by an operation in the database such as creating or copying items, or reordering a hierarchy of items, or by importing information into the database from an external file.
This table is used to:
- Check if a PDUID has been used
- Find the PDUID for a given item identity
- Find the item identity for a given PDUID
- Find the next UID to be used
Entries in the table are marked deleted when the last instance of the corresponding database item is deleted.
Selective Reuse of PDUIDs
PDUIDs are never reused for different pieces of information, but they are reused for the same piece of information. This means that if a piece of information is deleted, its entry in the PDUID table is marked deleted, but the entry remains in the table. If that piece of information is ever recreated, then the PDUID table entry will be found, marked active, and the PDUID recorded in the table entry will be applied to the piece of information.
If items are auto-numbered, then the items’ identities are never reused and so PDUIDs are never reused.
For items that are not auto-numbered, or do not support auto-numbering (such as diagram, specification or data definition items in models), then PDUIDs can be reused. PDUIDs can also be reused when information is imported, and previously-deleted items are found in the PDUID table and their PDUIDs reused. This can be over-ridden on import as will be discussed later.
Example Scenario
As an example, consider the scenario:
- Create item r1, the assigned PDUID is: 020A3857A3FRED__0000000001
- Create item r2, the assigned PDUID is: 020A3857A3FRED__0000000002
- Delete item r1
- Create item r3, the assigned PDUID is 020A3857A3FRED__0000000003. Note that the UID in this PDUID is not 1 (which is now available since r1 was deleted), it is 3, because new PDUIDs always use the next UID value.
- Create item r4, the assigned PDUID is: 020A3857A3FRED__0000000004
- Create item r1, the assigned PDUID is: 020A3857A3FRED__0000000001 because the original PDUID table entry for r1 has been found and marked active and its PDUID has been reused so that the new item r1 is assigned the same PDUID as the original item r1.
Reuse of PDUIDs on Import
The reuse of PDUIDs is the correct approach as it ensures that a given item always has the same identity, regardless of what happens during the life of a project.
If, for whatever reason, this is not the behaviour that you want, then use auto-numbered items so that every item will be guaranteed to have a new identity and hence guaranteed to also have a new PDUID. Since auto-numbering makes the reuse of item identities impossible; auto-numbering also ensures that it is impossible to reuse PDUIDs.