Welcome to the July 2023 newsletter from 3SL!
This newsletter contains a mixture of news and technical information about us, and our requirements management and systems engineering tool “Cradle”. We would especially like to welcome everyone who has purchased Cradle in the past month and those who are currently evaluating Cradle for their projects and processes.
We hope that 3SL and Cradle can deliver real and measurable benefits that help you to improve the information flow within, the quality and timeliness of, and the traceability, compliance and governance for, all of your current and future projects.
If you have any questions about your use of Cradle, please do not hesitate to contact 3SL Support.
PDUIDs
When we work with information, we need a way to distinguish each piece of information from all other pieces of information so we can be sure we have found what we were searching for. We do this by marking each piece of information in a unique way.
For information in databases, the markings are unique values called keys or identities. A piece of information can have multiple identities, each for a different purpose. For example, although a company’s payroll system is likely to identify each person by a unique Employee ID, each person’s details will also include their governmental tax ID (such as a National Insurance number, a Unique Taxpayer Reference, a Sozialversicherungsnummer or a Social Security Number). This tax ID will also be unique and so could also be used as an identity for that person’s information.
Cradle has two forms of identity, item identities and Project Database Unique IDs (PDUIDs).
We will publish a series of blog posts about PDUIDs, describing what they are, how to view them, how to use them, and how PDUIDs can be managed when you import information into your databases.
Item Identities
There are several basic item types in Cradle. Each basic item type uses a different combination of attributes to create a unique Item ID for items of that type:

An item is identified by this Item ID and a unique Instance ID, typically a version and draft.
PDUID Structure
Project Database Unique IDs (PDUIDs) are a single, consistent, numbering system for all database information. Each PDUID is a 26 character string that contains a Database ID to identify a Cradle system, a Project ID to identify a project database and a Unique ID:
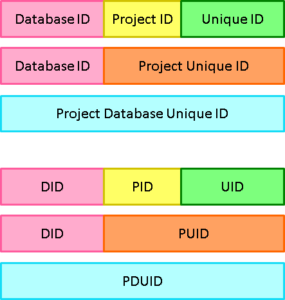
A PDUID references all instances of an item. Therefore the combination of a PDUID and an Instance ID (a version and draft) will identify a specific item. So, this is an alternative to the Item ID and Instance ID and has the advantage of being consistent and a single numbering sequence for all types of item.
Further Details
For further details in this part 1 of a description of PDUIDs, please see the full blog entry here.
Remote Databases
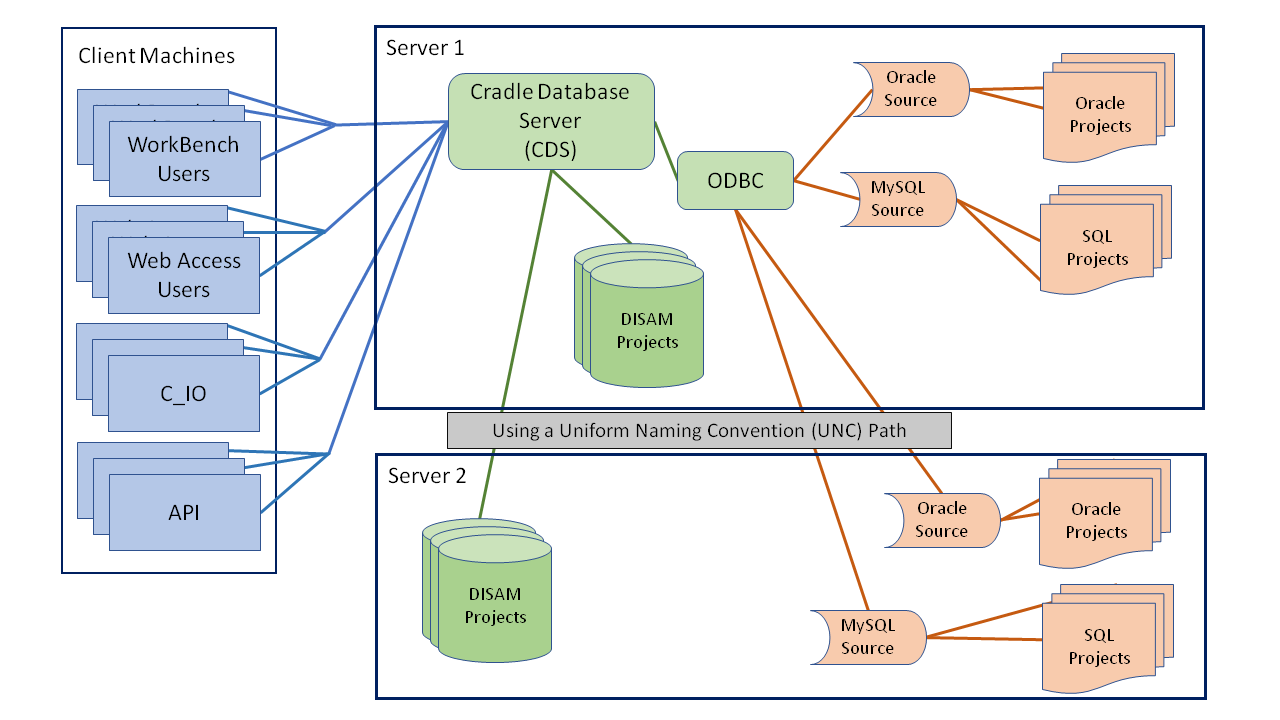
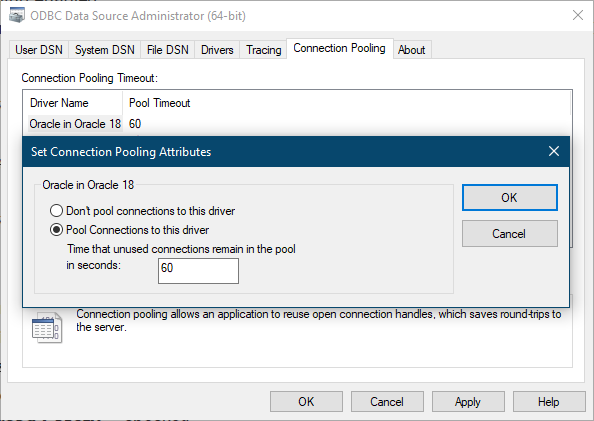
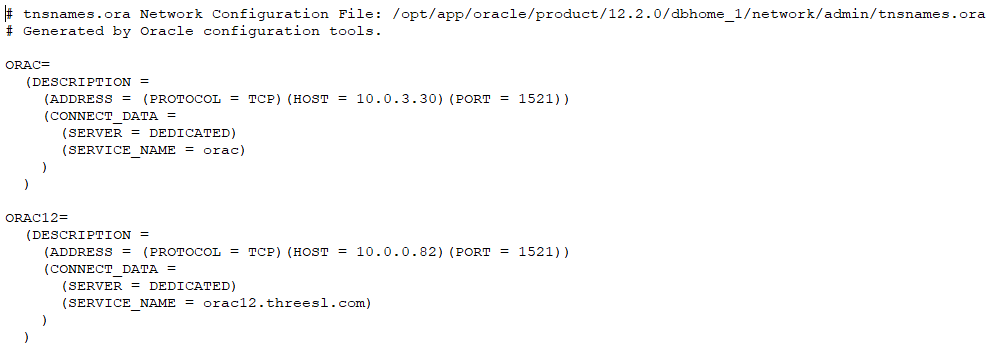
A Cradle system can contain any number of databases. For the best performance, we recommend that databases are stored on disks connected to the machine that runs your Cradle Database Server (CDS). But, this may not be possible.
For example:
- The local system may not have enough disk space available
- The information in the database may be classified and must be stored separately
Here each database will be stored on a remote filesystem that must be referenced by a pathname so the CDS can work with it.
Further Details
For further details of remote databases, please see the full blog entry here.
Over Half Way Through the Year
It’s true; the 2nd July marked the halfway point of the calendar year. That went fast didn’t it?
It feels like we only just celebrated the New Year and now we are six months away from doing it all over again.
At this time of year, it is good to reflect on what’s already passed and what is to come this year. Here are some ways that might help if you are looking to refocus and recharge over the summer months.
Check in on Team Goals
- How are the goals the team set at the beginning of the year going?
- When was the last time your team reviewed them?
Now is a great time to reflect on any progress. Is your team on track? Is everybody on the same page?
Whatever the progress so far this year, there will be lessons to be learnt from it. It’s time to put an action plan in place for the remainder of the year. Now is a good time to get the team goals back on track:
- Ask who do you need to help achieve those goals?
- What’s the best way to communicate with them?
- Is there an alternative way to achieve them?
Communication
Summer can be especially busy; school summer holidays, weekly events, fewer people in the office, and various demands can bring stress to everyone.
With all these additional activities going on, it’s easy for people to get distracted, lost and even burnt out.
Now is a great time to contact your team, employees and other connections. It can be as simple as a chat over a cup of coffee, a walk and talk or a business/working lunch. This will allow you to connect in a more casual way, which in turn, can help strengthen the link between you and your team.
Help your Team Avoid a Summer Decline
It’s no surprise that productivity can fall off a cliff when the sun comes out! Thoughts of ice cream, beer gardens and future holidays can lead our minds to wander off and our focus can end up in the bin.

Now is a good time to prepare your team and business to avoid any slump.
Congratulate your team on their efforts so far this year. One way to keep the momentum going is to set small achievable goals, something that can be done within a week to a month can help. As you complete and reach each one, the team will get a boost.
Having weekly/monthly meetings can allow the team to see those goals that have been achieved. Using metrics, dashboards and graphs can help your team see the progress made each week, month, year or more.
This progress will give reasons to celebrate and that can only be a good thing!
Remember: the team working together will make the dream work!
Feedback
We continue to receive positive feedback from our customers. We really appreciate ALL feedback, as this helps us to assess and improve both the products and services we provide.
In June, we provided a Cradle training course to one of our customers in Australia. They kindly sent the following feedback:
“Extremely informative classes. We are very appreciative of the customised content tailored for our envisaged use of the tool”
Independence Day (4th July)
4th July was a federal holiday in the United States commemorating the Declaration of Independence which was ratified by the Second Continental Congress on July 4th 1776, establishing the United States of America.
Social Media
We commemorated #DDay – 79 years ago. “We will remember them“:

Some of our customers, both old and new, attended various shows/exhibitions etc, e.g.:
- @ZFGroup at AutoTech Detroit
- @the_MTC_org at Smart Factory Expo
- @Alstom at @VivaTech
- @MirionHQ at TRTR Research and Training Reactors Conference
@SercoGroup announced they have been awarded nine contracts to help the #IRIDE space programme. This programme is led by the Italian government and implemented by the European Space Agency. This is one of the most amibitous Earth Observation programmes in Europe.
With electric vehicles taking over the roads, our customer @Enphase talked about EV chargers.
Looking Back
Last month we discussed:
We would also like to thank all attendees on our Configuration Management course which we provided in June.
Still to Come this Month
- Project Administration Course – July 18th to 19th
- Cradle Introduction Course – July 25th to 26th
Your Highlights!
If you have any company news or achievements that you would like 3SL to share in any of our newsletters then please let us know.