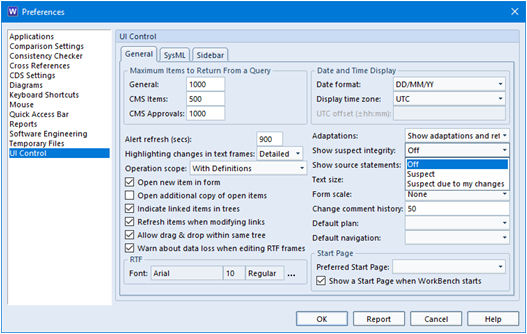
Changes to 3SL Bank Account Numbers
In response to the 2008 financial crisis, the UK Government has decided that all major banks must protect their personal, retail and most business banking operations from their more risky, often speculative, investment banking and international banking operations.

Most major banks in the UK will do this by creating a new ‘ring fenced‘ banking operation that is protected from future problems in the financial markets.
Most of the UK’s major banks will effect this change in April 2018.
For 3SL, these banking changes will mean that there will be a new BIC (bank identifier code) within the IBAN (international bank account number) of all of our bank accounts. In effect, all of the IBANs for our bank accounts will change in April 2018.
It is also possible that banking changes may effect another part of our bank account numbers, called the sort code (similar to the ATA, routing number or branch number codes in other countries’ banking systems). If there is a change to our sort code, the change is likely to occur in January 2018.
If you are an international supplier to 3SL, or one of our international customers, then it is possible that our IBANs will change in January 2018, and they will definitely change in April 2018 when the new ‘ring fenced’ bank in Barclays PLC receives its new BIC.
All of these changes are being completed in advance of the UK Government’s deadline of January 2019.
Our current IBANs will remain available for 36 months after the change in April 2018.
We apologise for the inconvenience that these changes will cause to our UK and international customers and suppliers.
Updates:
6th June 2018 – Barclays have confirmed the new SWIFT BIC code is BUKBGB22. Our sort code and account numbers have stayed the same but our IBAN numbers have changed. Please contact salesdetails@threesl.com to request our IBAN numbers.